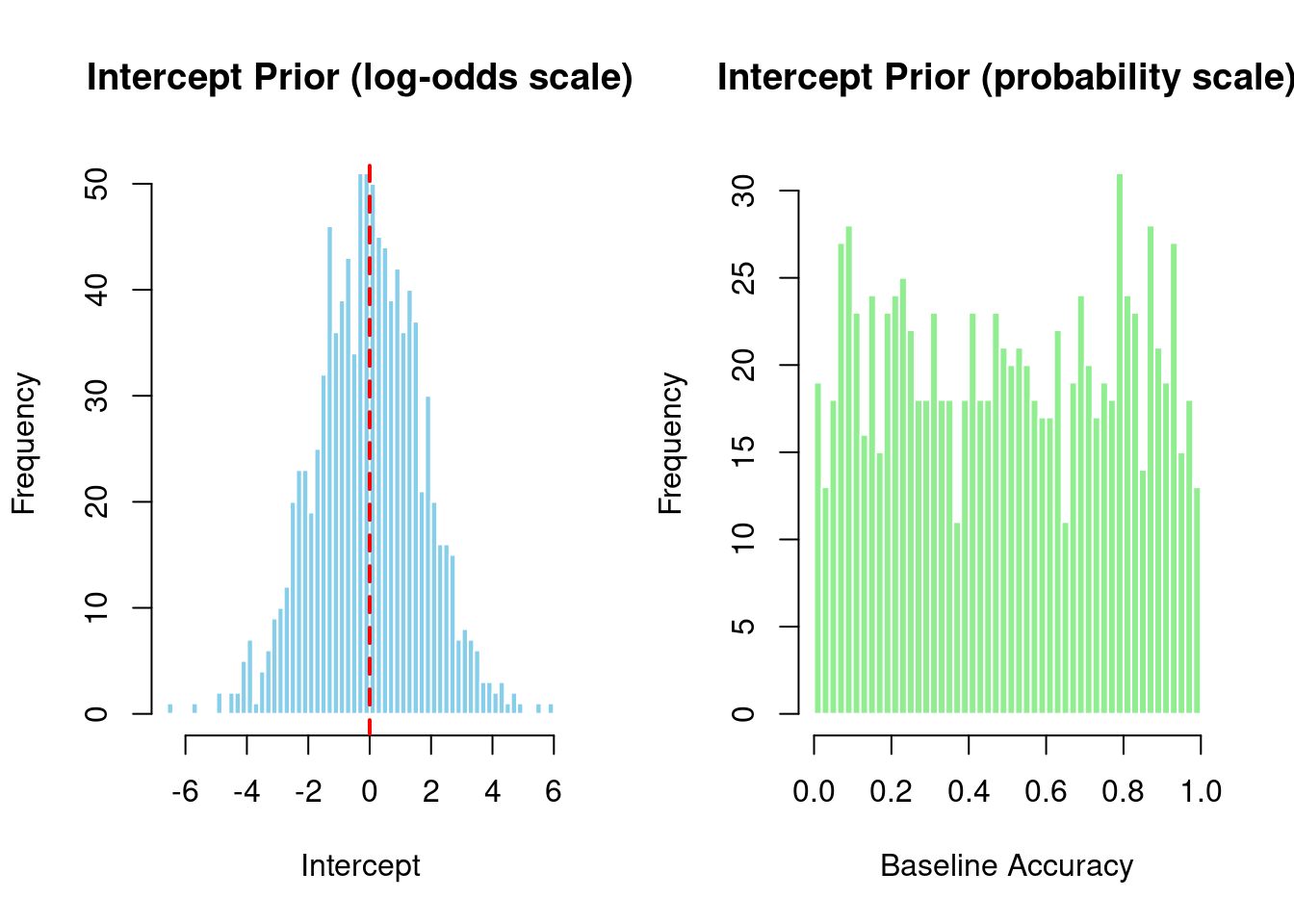
brms uses weakly informative priors by default (not completely flat). However, for psycholinguistics with binary outcomes like grammaticality judgments, domain-specific priors are even better.
1.1.1 What is a Prior?
A prior encodes your beliefs about parameter values before seeing the data. In Bayesian inference:
Types of priors: - Flat priors: No information - any value equally likely (bad: implies ignorance) - Weakly informative: Gentle regularization - allows data to dominate - Domain-specific: Based on domain knowledge - prevents unreasonable values
1.1.2 Default Intercept Prior for Binary Data
The default intercept prior for binary models is data-independent (unlike continuous models):
cat("\n→ Notice: Intercept prior is the SAME for both datasets!\n")
→ Notice: Intercept prior is the SAME for both datasets!
Show code
cat("→ For binary models, defaults DON'T adapt to data scale.\n")
→ For binary models, defaults DON'T adapt to data scale.
Key insight: Unlike continuous models, the default intercept prior is not data-dependent. This is actually convenient! However, the default slope prior is still flat and improper.
1.2 Default brms Priors for Binary Models
When you don’t specify priors for a binary outcome model, brms assigns defaults:
Intercept: student_t(3, 0, 1.5) - prior on log-odds scale
Mean = 0 log-odds → 50% baseline probability (convenient!)
Does NOT depend on your data
Slopes (b): (flat) - improper uniform prior over (-∞, +∞)
No information: any effect size equally likely
Technically improper (doesn’t integrate to 1)
SD (random effects): exponential(1) with lower bound 0
Encourages moderate between-subject/item variation on log-odds scale
Cor (correlations): lkj(1) - uniform over all correlation matrices
1.3 Setting Weakly Informative Priors for Binary Data
For grammaticality judgments and other binary outcomes, specify priors based on domain knowledge:
Show code
# Define priors explicitly for binary datagram_priors <-c(prior(normal(0, 1.5), class = Intercept), # baseline accuracy near 50-80%prior(normal(0, 1), class = b), # moderate effect sizesprior(exponential(1), class = sd), # random effects variationprior(lkj(2), class = cor) # slight preference for lower correlations)cat("Our weakly informative priors:\n")
Our weakly informative priors:
Show code
print(gram_priors)
prior class coef group resp dpar nlpar lb ub tag source
normal(0, 1.5) Intercept <NA> <NA> user
normal(0, 1) b <NA> <NA> user
exponential(1) sd <NA> <NA> user
lkj(2) cor <NA> <NA> user
1.3.1 Why These Numbers?
1.3.1.1normal(0, 1.5) for Intercept
Mean = 0 on log-odds scale → plogis(0) = 50% accuracy
cat("Student-t allows extreme values 1.7x more likely than normal!\n")
Student-t allows extreme values 1.7x more likely than normal!
When to use each: - Student-t: Default choice (conservative, robust to outliers in your beliefs) - Normal: When you have strong domain knowledge about plausible effect ranges (better for binary data in well-designed experiments)
1.4 Checking Priors with Prior Predictive Checks
Before fitting your model, verify that priors generate sensible predictions:
Show code
library(bayesplot)# Fit model with priors only (no likelihood)prior_only_fit <-brm( correct ~ condition + (1+ condition | subject) + (1| item),data = gram_data_typical,family =bernoulli(),prior = gram_priors,sample_prior ="only", # KEY: only sample from priors, ignore datachains =2, iter =1000,verbose =FALSE, refresh =0)# Generate prior predictionscat("Prior predictive check:\n")
Prior predictive check:
Show code
cat("Prior-predicted accuracies (should be realistic):\n")
cat("→ Expects B to increase accuracy by roughly 5-30% relative to A\n")
→ Expects B to increase accuracy by roughly 5-30% relative to A
1.5 Complete Workflow Example
Here’s a template for analyzing a new grammaticality judgment dataset:
Show code
# STEP 1: Load and prepare datagram_study_data <-read.csv("path/to/your/gram_data.csv")# STEP 2: Define priors based on your domain knowledgemy_priors <-c(prior(normal(0, 1.5), class = Intercept), # adjust if you expect very high/low baselineprior(normal(0, 1), class = b), # adjust if you expect larger effectsprior(exponential(1), class = sd),prior(lkj(2), class = cor))# STEP 3: Check default priorsdefault_priors <-get_prior( grammatical ~ condition + (1+ condition | subject) + (1| item),data = gram_study_data,family =bernoulli())print(default_priors)# STEP 4: Fit prior-only model for checkingprior_check <-brm( grammatical ~ condition + (1+ condition | subject) + (1| item),data = gram_study_data,family =bernoulli(),prior = my_priors,sample_prior ="only",chains =2, iter =1000,cores =4,verbose =FALSE, refresh =0)# STEP 5: Visualize prior predictionspp_check(prior_check, type ="stat", stat ="mean", prefix ="ppd") +labs(title ="Prior Predictive Check: Overall Accuracy")# STEP 6: If priors look good, fit full modelfinal_model <-brm( grammatical ~ condition + (1+ condition | subject) + (1| item),data = gram_study_data,family =bernoulli(),prior = my_priors,chains =4, iter =2000,cores =4,verbose =FALSE, refresh =0)# STEP 7: Check posterior predictive (see 03_posterior_predictive_checks_gram.qmd)pp_check(final_model, type ="stat", stat ="mean", prefix ="ppd")
1.6 Summary
Key takeaways:
Don’t use flat priors - they’re uninformative and often lead to weak regularization
For binary models, defaults are data-independent - but slopes are still flat!
Specify priors explicitly based on domain knowledge (baseline accuracy, expected effect sizes)
Use prior predictive checks - verify that priors generate plausible predictions before fitting
Normal() is better than student_t() when you have domain knowledge - more concentrated around plausible values
Practical guidance for binary data: - Baseline accuracy: Use normal(0, 1.5) for intercept to allow 5-95% range - Effect sizes: Use normal(0, 1) for slopes to expect ~1.7× odds ratio between conditions - Between-subject variation: Use exponential(1) to encourage moderate variation
Next steps: - See 02_prior_predictive_checks_gram.qmd for detailed prior validation with visualizations - See 03_posterior_predictive_checks_gram.qmd for checking if the fitted model makes sense